



网易云评论爬虫
前言
最近在学习python爬虫,看了b站爬虫视频其中的有关网易云评论的爬取,发现其中其中只能爬取一页的评论,最多可爬1000条
可是想要获取一首歌的全部评论(1000条),2000条,5000条,10000条,100000条就需要对其中的参数进行更改,下面我来教大家从头开始网易云音乐中一首歌的全部评论的获取。
使用selenium来实现
因为要获取全部的评论,我首先想到的最简单的方法就是使用selenium,因为它相当于是在模仿人的操作来点击浏览器,只要人你能看到的,他都能进行抓取。不过就是它可以代替你去点击鼠标(鼠标寿命+n),并且可以自动的将数据进行存储。
在开始之前,我们首先创建一个python文件,并导入相应的库。
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
我们首先打开浏览器,进入网易云音乐的官网打开你想要抓取评论的一首歌,或者直接点击通过点击网易云进入搜素。我选择的是告五人《唯一》。我使用的浏览器是Chrome,所以应该先实例化一个Chrome类,然后传入歌曲的网址,并切换进入frame。
web = Chrome()
web.get('https://music.163.com/#/song?id=1807799505')
web.switch_to.frame(0)
我们需要下拉滚轮来找到评论的位置,因为selenium是模仿人在操作浏览器的,并且该页面是动态加载的,所以我们还需要让模拟下拉滚轮的操作,来实现整个页面完全加载,可以通过js来实现。
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight'
web.execute_script(js)
再通过点击F12或者鼠标右键检查打开开发者工具,再点击左上角的箭头,定位到评论的位置,如图:

我们可以发现,每一条评论都是class="itm"。所以,我们可以使用CSS选择器来对评论进行筛选
divs = web.find_elements_by_css_selector('.itm')
在最新的selenium中,不再使用上述方法,应改为:
divs = web.find_elements(By.CSS_SELECTOR, '.itm')
然后点开其中的一个标签 ,找到评论具体的位置
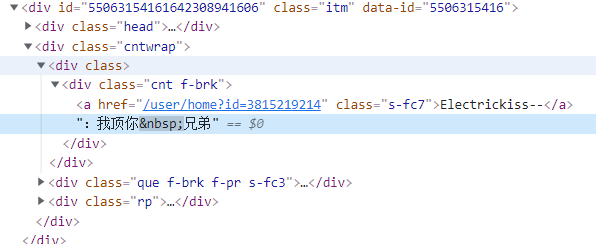
我们可以发现评论的具体位置在class="cnt f-brk"中,我们再次使用CSS选择器进行评论的筛选,并将得到的评论持久化存储。
cnt = div.find_element_by_css_selector('.cnt.f-brk').text
cnt = cnt.replace('\n', ' ')
with open('comments.txt', mode='a', encoding='utf-8') as f:
f.write(cnt + '\n')
最后再定位到下一页并点击即可实现翻页的目的。
web.find_element_by_css_selector('.znxt').click()
time.sleep(0.5)
你也可以通过设置为无头浏览器模式来后台进行爬取,即不显示抓取过程。
opt = Options()
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
web = Chrome(options=opt)
selenium总结
通过selenium实现网易云评论的抓取相对简单,代码量较少。但是,selenium的速度实在是太慢了(60000多评论竟然要用几十分钟,等崩溃了😵😵😵),而且我发现抓取的评论并不全(你可能会说:“你不是说selenium是模仿人操作的吗?怎么可能不全?”)那是因为你看到的也不全,所以它抓取到不全。每两页之间少了一些评论。所以我放弃了这种方法。
selenium完整代码
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
opt = Options()
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
web = Chrome(options=opt)
# web = Chrome()
web.get('https://music.163.com/#/song?id=1807799505')
web.switch_to.frame(0)
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight'
web.execute_script(js)
for click in range(2000):
# divs = web.find_elements_by_css_selector('.itm')
divs = web.find_elements(By.CSS_SELECTOR, '.itm')
for div in divs:
cnt = div.find_element_by_css_selector('.cnt.f-brk').text
cnt = cnt.replace('\n', ' ')
with open('comments.txt', mode='a', encoding='utf-8') as f:
f.write(cnt + '\n')
web.find_element(By.CSS_SELECTOR, '.znxt').click()
time.sleep(0.5)
web.quit()
使用requests方法
requests才是爬虫的浪漫,不过requests实现起来比较麻烦,但是却可以爬取到所有的评论信息。(还得是咱requests,selenium是什么东西!!!)
首先,新建python文件,然后调库(只会调库)。
import time
import requests
from Crypto.Cipher import AES
import json
from base64 import b64encode
import datetime
import csv
其中requests用作请求发送(我们的根本);time和datetime是用来时间戳转换以及格式化输出时间(精确到毫秒级);其他的库主要是用作加密参数来模仿请求。
注:本项目用到了代理池,需要先搭建个人代理池才能使用,因为可能会被封IP。代理池的搭建可参考GitHub - Python3WebSpider/ProxyPool: An Efficient ProxyPool with Getter, Tester and Server。以后我也会出一个相关的博客。
还是先打开开发者工具,点击Network然后刷新,找到评论在get?csrf_token= 数据包中,我们可以拿到评论的请求网址https://music.163.com/weapi/comment/resource/comments/get?csrf_token=
且可以发现每一页的请求网址都是一样的,所以是由相关的参数来控制页码数。我们点击Payload查看具体的参数,结果却的发现参数是这样的:
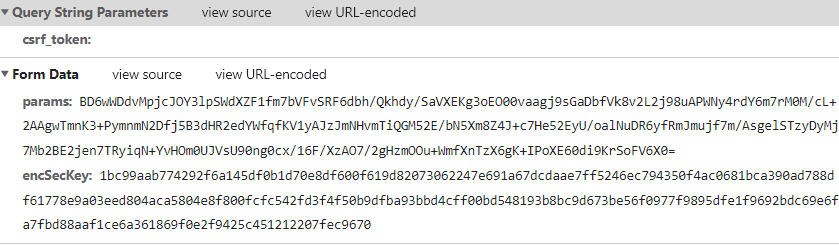
显然,参数是加密的(不是人看的),我们可以通过复制该参数来实现该页的爬取,可是这么多页的评论不可能每一页都来复制粘贴(那还不如用selenium算了)。所以,我们必须找出他的加密逻辑。
我们点击和Network在同一行的Initiator按钮,再点击第一个,通过加断点调试,我们可以得到加密前的数据
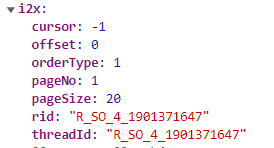
然后在得到该参数的那一行再打一个断点(我的断点在8054行,return t2x.be2x(Y2x, Bh0x)),整体位置可见下图:
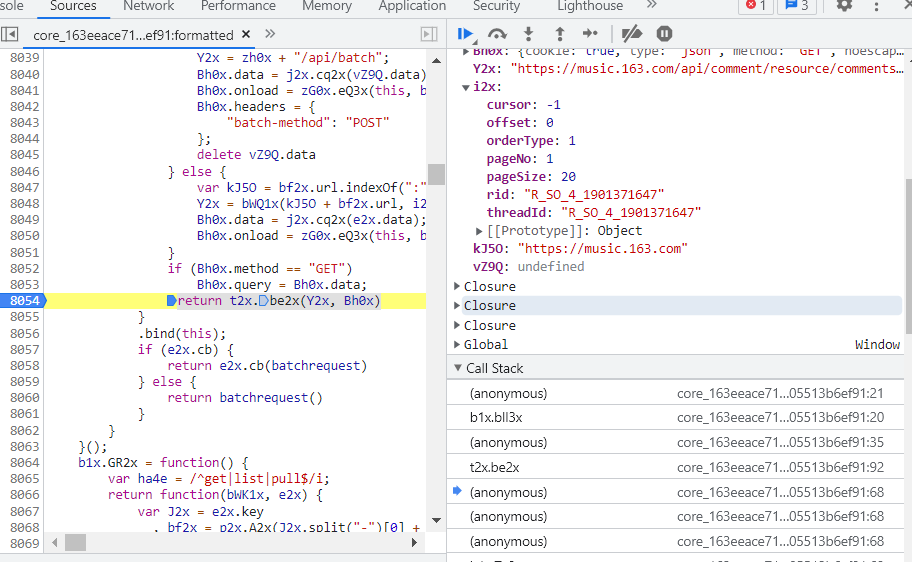
然后狂点蓝色的箭头至页面加载完毕。然后点第二页,可以得到下列参数
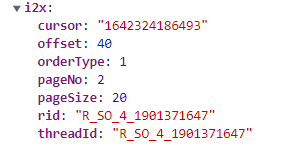
然后继续狂点蓝色箭头至页面加载加载完毕,然后点第三页,可以得到下列参数
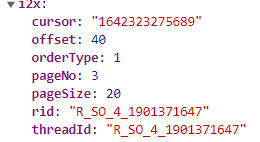
同理可以得到后面的页码参数,经过对比可以发现:参数rid和threadId这两个参数是相同的,都是’R_SO_4_'加歌曲的id号;pageSize参数为每一页的最大评论条数(经过实验可知,该参数最大为1000);pageNo参数为页码数,从1开始;orderType参数从字面意思理解应为排序方式,固定为1不变;offset参数不知其具体的含义,但是能通过对比发现,除了第一页为0以外,其他的页码都为40,也相当于固定值;cursor参数通过实验可知其为上一页最后一条评论的时间戳。这些参数的具体含义搞清楚后,我们就可以编写具体的代码了。
通过网上现有的一些资源可知,参数的加密过程为AES-CBC,并且加密了两次,也可通过js逆向分析得到。这些在网上已经有很多的例子了,我就不再一一赘述了,具体的AES加密可以移步百度。网易云实现加密的js代码如下:
function a(a) {
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1)
e = Math.random() * b.length,
e = Math.floor(e),
c += b.charAt(e);
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b)
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a)
, f = CryptoJS.AES.encrypt(e, c, {
iv: d,
mode: CryptoJS.mode.CBC
});
return f.toString()
}
function c(a, b, c) {
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) {
var h = {}
, i = a(16);
return h.encText = b(d, g),
h.encText = b(h.encText, i),
h.encSecKey = c(i, e, f),
h
}
我们可以很容易用python实现该加密过程,而且网上也有很多现成的例子,我们可以借鉴一下(抄就完事,不行再改)。
我的整个加密过程如下:
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token=' # 请求评论的网址
proxy_url = 'http://localhost:5555/random' # 代理池请求网址
# e = '010001'
# f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g = '0CoJUm6Qyw8W8jud' # 第一次加密密钥
i = 'wwmZrdkJSOJzaKoz' # 第二次加密密钥
enSecKey = "249f3b495e076d4c79d155f2c3a8a9b39522f0076b06f778c60f8e8581459eefb0d0291695c8237091d50960f0458fc9640308f7f4f45a9da88e6038f82994fc515ef771d81bbc46ff1c4c929256b652d8a63793233f5c23c6b8e997676647deb1bc0db8e14759c27a340da6e4570e3b51bfa209ecadebc4fae97b71b787102e" # 该参数可直接复制一次请求成功后的该值
headers = {
'User-Agent': 'Chrome/10',
} # UA伪装
def get_params(data1):
first = enc_params(data1, g)
second = enc_params(first, i)
return second
def to_16(data3):
pad = 16 - len(data3) % 16
data3 += chr(pad) * pad
return data3
def enc_params(data2, key):
iv = "0102030405060708" # 初始化偏移量
data3 = to_16(data2)
aes = AES.new(key=key.encode('utf-8'), IV=iv.encode('utf-8'), mode=AES.MODE_CBC)
bs = aes.encrypt(data3.encode('utf-8'))
return str(b64encode(bs), 'utf-8')
其中的to_16()方法是AES加密前必须要进行数字的处理:AES每次加密128位,每次加密需要16位16进制数,如果不足16位的话,就需要在后面添加一些数补足16位,具体规则位:差几位就在后面补几个几的ASCII码对应的字符,比如差3位就需要在后面补3个chr(3);如果正好是16的倍数,则需要在后面加16个chr(16)
if j == 1:
data = {
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "1000",
"rid": "R_SO_4_" + song_id,
"threadId": "R_SO_4_" + song_id
}
else:
data = {
"csrf_token": "",
"cursor": cursor,
"offset": "40",
"orderType": "1",
"pageNo": str(j),
"pageSize": "1000",
"rid": "R_SO_4_" + song_id,
"threadId": "R_SO_4_" + song_id
}
从上面的分析中,我们可以知道,相关参数的含义,其中的第一页和其他页的整个思路不同,所以需要if来进行条件控制,并且我每一页爬取的评论数为1000条。
def get_one_page(j, cursor):
# print(response.text)
response = get_html(j, cursor)
json_dict = json.loads(response.content.decode('utf-8'))
# print(json_dict)
users_data = []
try:
for comment in json_dict['data']['comments']:
user_data = []
nickname = comment['user']['nickname']
user_data.append(nickname)
userid = comment['user']['userId']
user_data.append(userid)
ti = comment["time"]
timearray = datetime.datetime.fromtimestamp(ti / 1000)
otherstyletime = timearray.strftime("%Y-%m-%d %H:%M:%S.%f")
user_data.append(otherstyletime)
like = comment["likedCount"]
user_data.append(like)
text = comment['content']
user_data.append(text)
users_data.append(user_data)
except KeyError:
pass
new_cursor = json_dict['data']['cursor']
return users_data, new_cursor
这个方法是用来获取一页中的所有评论信息,其中json.loads是用来将请求到的json数据转换为python对象用于后续的操作。然后定义了一个users_data列表用来存放每页的所有数据,然后取出每条评论中的昵称,用户ID,评论时间,点赞数,以及评论内容加入到user_data中,再将user_data加入到users_data中,最后再拿到每页最后的时间戳,用来进行下一个页面的爬取。
def get_full_pages():
num = 1
cursor = ''
while True:
print(f'正在爬取第{num}页')
users_data, cursor = get_one_page(num, cursor)
num += 1
# csv存储
with open('pinglun\\网易云评论2.csv', mode='a', encoding='utf-8', newline='') as fp:
for n in users_data:
csv.writer(fp).writerow(n)
# sqlite数据库存储
# c.executemany(f"INSERT INTO id{song_id}(昵称, 用户ID, 评论时间, 点赞数, 评论内容) values (?,?,?,?,?)", users_data)
if not users_data:
print("爬取完毕!!!")
break
在进行全部页面爬取的时候一定要注意,千万不要使用for循环来控制爬取的页数,不然会报错,我也不清楚为什么(for循环会第二次在加密的时候报错,可能是那个AES加密库的问题。我当时一直没有解决,如果有大佬知道为什么一定要告诉我)。但是用了while就又好了,我只能说神奇。在拿到每一页的数据之后,进行持久化存储。当users_data中没有数据时,跳出while循环。
requests总结
使用requests库来进行爬取,过程很艰难,会出现各种奇奇怪怪的问题,而且很麻烦,既要考虑参数加密,也要考虑数据提取。但是它的执行过程很快,并且可以爬取到所有评论。理论上这个过程不能使用多线程来同步爬取,因为在进行每一页爬取时必须知道前一页的cursor值,所以不好实现。但是我们可以通过多线程来爬取多首歌的评论,可以实现伪多线程
requests完整代码
import time
import requests
from Crypto.Cipher import AES
import json
from base64 import b64encode
import datetime
import csv
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token=' # 请求评论的网址
proxy_url = 'http://localhost:5555/random' # 代理池请求网址
# e = '010001'
# f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g = '0CoJUm6Qyw8W8jud' # 第一次加密密钥
i = 'wwmZrdkJSOJzaKoz' # 第二次加密密钥
enSecKey = "249f3b495e076d4c79d155f2c3a8a9b39522f0076b06f778c60f8e8581459eefb0d0291695c8237091d50960f0458fc9640308f7f4f45a9da88e6038f82994fc515ef771d81bbc46ff1c4c929256b652d8a63793233f5c23c6b8e997676647deb1bc0db8e14759c27a340da6e4570e3b51bfa209ecadebc4fae97b71b787102e" # 该参数可直接复制一次请求成功后的该值
headers = {
'User-Agent': 'Chrome/10',
} # UA伪装
def get_params(data1):
first = enc_params(data1, g)
second = enc_params(first, i)
return second
def to_16(data3):
pad = 16 - len(data3) % 16
data3 += chr(pad) * pad
return data3
def enc_params(data2, key):
iv = "0102030405060708" # 初始化偏移量
data3 = to_16(data2)
aes = AES.new(key=key.encode('utf-8'), IV=iv.encode('utf-8'), mode=AES.MODE_CBC)
bs = aes.encrypt(data3.encode('utf-8'))
return str(b64encode(bs), 'utf-8')
def get_proxy():
try:
resp = requests.get(proxy_url)
if resp.status_code == 200:
# print(resp.text)
return resp.text
return None
except ConnectionError:
return None
def get_html(j, cursor):
try:
proxy = get_proxy()
proxies = {
'http': 'http://' + proxy
}
if j == 1:
data = {
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "1000",
"rid": "R_SO_4_" + song_id,
"threadId": "R_SO_4_" + song_id
}
else:
data = {
"csrf_token": "",
"cursor": cursor,
"offset": "40",
"orderType": "1",
"pageNo": str(j),
"pageSize": "1000",
"rid": "R_SO_4_" + song_id,
"threadId": "R_SO_4_" + song_id
}
response = requests.post(url, data={
"params": get_params(json.dumps(data)),
"encSecKey": enSecKey
}, headers=headers, proxies=proxies)
if response.status_code == 200:
return response
else:
time.sleep(3)
return get_html(j, cursor)
except ConnectionError:
return get_html(j, cursor)
def get_one_page(j, cursor):
# print(response.text)
response = get_html(j, cursor)
json_dict = json.loads(response.content.decode('utf-8'))
# print(json_dict)
users_data = []
try:
for comment in json_dict['data']['comments']:
user_data = []
nickname = comment['user']['nickname']
user_data.append(nickname)
userid = comment['user']['userId']
user_data.append(userid)
ti = comment["time"]
timearray = datetime.datetime.fromtimestamp(ti / 1000)
otherstyletime = timearray.strftime("%Y-%m-%d %H:%M:%S.%f")
user_data.append(otherstyletime)
like = comment["likedCount"]
user_data.append(like)
text = comment['content']
user_data.append(text)
users_data.append(user_data)
except KeyError:
pass
new_cursor = json_dict['data']['cursor']
return users_data, new_cursor
def get_full_pages():
num = 1
cursor = '-1'
while True:
print(f'正在爬取第{num}页')
users_data, cursor = get_one_page(num, cursor)
num += 1
# csv存储
with open('pinglun\\网易云评论2.csv', mode='a', encoding='utf-8', newline='') as fp:
for n in users_data:
csv.writer(fp).writerow(n)
# sqlite数据库存储
# c.executemany(f"INSERT INTO id{song_id}(昵称, 用户ID, 评论时间, 点赞数, 评论内容) values (?,?,?,?,?)", users_data)
if not users_data:
print("爬取完毕!!!")
break
if __name__ == '__main__':
song_id = input('请输入歌曲id:')
get_full_pages()
评论区